
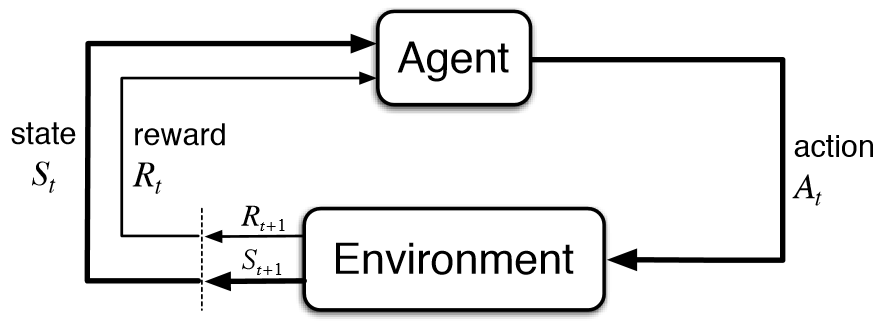
In alcune applicazioni l’output è rappresentato da una sequenza di azioni, in tal caso una singola azione non è importante, ciò che conta è la policy ovvero la sequenza di azioni corrette per raggiungere l’ obiettivo: un’azione è buona se fa parte di una buona politica.
In tal caso, il programma di Machine Learning dovrebbe essere in grado di valutare la bontà delle politiche e imparare dalle buone sequenze di azioni passate per essere in grado di generare una politica efficace.
Tali metodi di rinforzo dell’apprendimento sono chiamati algoritmi di apprendimento per rinforzo.
Un buon esempio è il gioco in cui una singola mossa di per sé non è così importante; è la sequenza di mosse giuste che è buona.
Una mossa è buona se fa parte di una buona politica di gioco.
Il gioco è una ricerca importante sia nell’intelligenza artificiale che nell’apprendimento automatico.
Questo perché i giochi sono facili da descrivere e, allo stesso tempo, sono piuttosto difficili da giocare bene.
Un gioco come gli scacchi ha un numero limitato di regole ma è molto complesso a causa del gran numero di mosse possibili in ogni stato e grande numero di mosse che un gioco contiene.
Una volta che abbiamo buoni algoritmi che possono imparare a giocare bene, possiamo applicarli anche ad applicazioni con utilità economica più evidente.
Un robot che naviga in un ambiente alla ricerca di una posizione obiettivo è un’altra area di applicazione dell’apprendimento per rinforzo.
In qualsiasi momento, il robot può muoversi in una delle numerose direzioni. Dopo una serie di prove, dovrebbe apprendere la corretta sequenza di azioni per raggiungere lo stato finale da uno stato iniziale, facendo questo il più rapidamente possibile e senza colpire nessuno degli ostacoli.
Un fattore che rende più difficile l’apprendimento per rinforzo è quando il sistema ha informazioni sensoriali inaffidabili e parziali. Ad esempio, un robot dotato di videocamera ha informazioni incomplete e quindi in qualsiasi momento si trova in uno stato parzialmente osservabile e dovrebbe decidere tenendo conto di questa incertezza ; ad esempio, potrebbe non conoscere la sua posizione esatta in una stanza, ma solo che c’è un muro alla sua sinistra. Un’attività può anche richiedere un’operazione simultanea di più agenti che dovrebbero interagire e cooperare per raggiungere un obiettivo comune.
Un esempio è una squadra di robot che giocano a calcio.