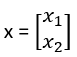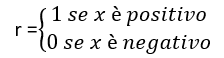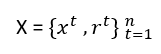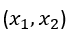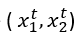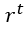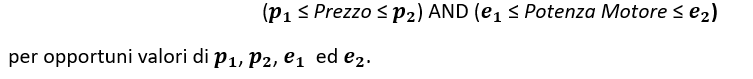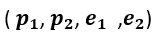Python, nato nel 1991 come linguaggio di scripting orientato agli oggetti, è diventato una forza dominante nel mondo della programmazione. Il suo creatore, Guido van Rossum, sviluppò Python presso il National Research Institute for Mathematics and Computer Science di Amsterdam. Oggi, questo linguaggio è ampiamente utilizzato in varie discipline, ma perché ha guadagnato così tanta popolarità?
Open Source e Comunità Attiva:
Python è un linguaggio open source, accessibile gratuitamente a tutti. La sua comunità è estremamente collaborativa e pronta ad assistere, rendendolo ideale per chiunque desideri imparare o risolvere problemi di programmazione.
Facilità di Apprendimento:
Rispetto ad altri linguaggi come C, C++, C# e Java, Python è notoriamente più facile da imparare. Questa caratteristica permette ai principianti di entrare rapidamente nel mondo della programmazione e consente agli esperti di aggiornarsi con facilità.
Leggibilità del Codice:
La sintassi di Python è chiara e leggibile, facilitando la comprensione del codice. Questo aspetto contribuisce alla sua diffusa adozione nell’ambito didattico.
Librerie e Produttività:
La libreria standard di Python è estremamente ricca, e ci sono migliaia di librerie open source sviluppate indipendentemente. Questo permette ai programmatori di scrivere codice più velocemente e di affrontare compiti complessi in poche righe.
Applicazioni e Sviluppo Web:
Python è utilizzato ampiamente nello sviluppo web, con framework come Django e Flask. È anche alla base di numerose applicazioni famose come Dropbox, YouTube, Reddit, Instagram e Quora.
Supporto a Diversi Paradigmi di Programmazione:
Python supporta paradigmi come la programmazione procedurale, funzionale, orientata agli oggetti e riflessiva. Questa flessibilità rende Python adatto a una vasta gamma di applicazioni e stili di programmazione.
Programmazione Concorrente Semplificata:
Grazie a funzionalità come asyncio e async/await, Python semplifica la programmazione concorrente a thread singolo, riducendo la complessità di scrittura, debugging e manutenzione del codice.
Ampia Adozione nell’Intelligenza Artificiale e Finanza:
Python è popolare nell’intelligenza artificiale, con la crescita esplosiva di questo settore. È anche ampiamente utilizzato nella comunità finanziaria.
Alta Richiesta nel Mercato del Lavoro:
I programmatori Python sono fortemente ricercati in diverse discipline, specialmente nelle posizioni legate alla data science, e sono tra i più remunerati nel mercato del lavoro.
In sintesi, Python si è affermato come un linguaggio versatile, potente e amato dalla comunità, mantenendo la sua posizione di leader nel panorama della programmazione.
Esistono numerosi framework javascript ognuno con la sua lista di vantaggi e svantaggi. Già con la prima versione di Angular i programmatori avevano gli strumenti per progettare e sviluppare applicazioni Javascript su larga scala ma con il passare del tempo sono emersi numerosi difetti. La seconda versione è stata implementata raccogliendo ed ascoltando i feedback della community per ben cinque anni.
La nuova versione di Angular è più semplice per i programmatori rispetto alla precedente; infatti con Angular 1 erano i programmatori a dover capire le differenze tra Controllers, Services, Factories e Providers. Angular 2 è anche più snello come framework e permette di concentrarsi sulla creazioni di classi, inoltre viste e controller sono stati rimpiazzati dai components che possono essere descritti come una versione raffinata delle derictives; tutto questo ha reso la nuova versione di Angular molto più semplice. I componenti di Angular 2 sono molto più semplici da capire.
Angular 2 è stato scritto in typescript, un estensione di javascript che implementa nuove features di ES2016+. Anche l’ecosistema per consentire di programmare con la nuova versione di Angular è stato arricchito con nuovi strumenti che permettono di velocizzare la scrittura del codice (IDE). Questo aspetto è importantissimo per i programmatori che vengono supportati notevolmente nell’apprendimento della nuova versione di Angular.
Anche se la nuova versione di Angular rappresenta una rottura con la versione precedente, sussistono dei punti di continuità rappresentati dalla dependency injection che semplificheranno la vita dei programmatori impegnati nella migrazione da altre librerie come React.
Angular 2 è stato progettato anche per dispositivi mobile e, nello specifico, ottimizzato per la ridotta capacità di calcolo rispetto ai computer tradizionali. Questa ottimizzazione ha reso l’esecuzione delle applicazione Angular base ancora più performanti in termini di reattività.
Come Reat anche Angular sfrutta il pre-rendering dell’ HTML su server o web worker al fine di migliorare l’esperienza utente.
Grazie all’integrazione con Nativescript, Angular 2 è utilizzabile per la realizzazione di app su dispositivi mobile. Inoltre, Ionic ha lavorato ad Angular 2 per sfruttare al meglio le funzionalità dei dispositivi mobile.
La prima versione di Angular ha fornito ai programmatori web un framework altamente flessibile per lo sviluppo di applicazioni. Questo è stato un cambiamento drammatico per molti programmatori web e, sebbene quel framework fosse utile, è diventato evidente che spesso era troppo flessibile. Nel tempo, le best practice si sono evolute ed è stata approvata una struttura guidata dalla community.
Angular 1.x ha cercato di aggirare varie limitazioni del browser relative a JavaScript. Ciò è stato fatto introducendo un sistema di moduli che utilizzava la dependency injection. Questa modalità era nuova, ma sfortunatamente presentava problemi con gli strumenti, in particolare la minimizzazione del codice (tecnica utilizzata per ridurre il tempo di caricamento delle app web based e minimizzare il tempo di utilizzo della banda) e l’analisi statica.
Il linguaggio Javascript è formalmente conosciuto come “EcmaScript”. La nuova versione di javascript , conosciuta come “ES6” offre un numero di caratteristiche che estende la potenza del linguaggio.
ES6 però non è totalmente supportato dai browser odierni, quindi, deve essere tradotto in ES5. Per far fronte a questa mancanza si può usare TypeScript che è il linguaggio usato dal team di Angular per scrivere Angular e che viene compilato in ES5 grazie al suo transpiler. In definitiva, mediante TypeScript Angular utilizza features di ES6 successivamente tradotto in ES5 .
JavaScript è stato creato nel 1995, ma il linguaggio è ancora largamente utilizzato oggi. Ci sono sottoinsiemi, superinsiemi, versioni attuali e l’ultima versione ES6 che offre molte nuove funzionalità.
Il modo migliore per parlare di apprendimento supervisionato è quello individuare un caso semplice, ovvero l’apprendimento di una classe dai suoi esempi positivi e negativi, e successivamente generalizzare per di più classi. Come ultimo step per trattare l’apprendimento supervisionato bisogna parlare di regressione, dove gli output sono continui.
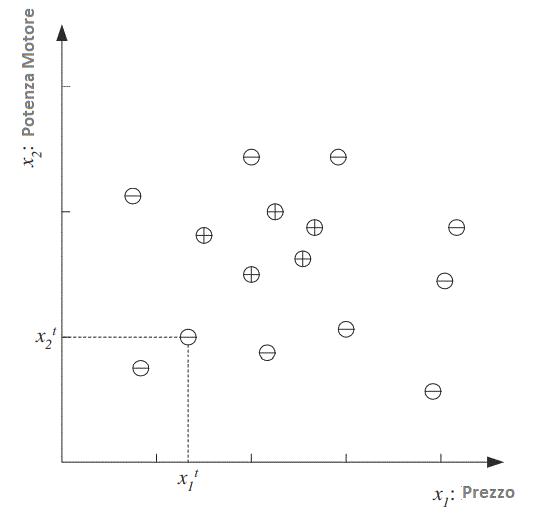
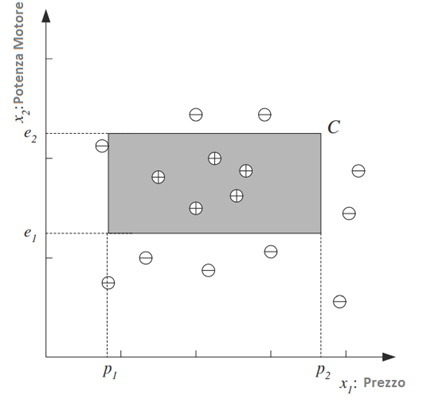
Diciamo che vogliamo imparare la classe C che identifica tutte le “auto familiari“. Abbiamo una serie di esempi di auto e abbiamo un gruppo di persone a cui mostriamo queste auto. Le persone guardano le auto per etichettarle; per esempi positivi intendiamo le auto che credono siano auto di famiglia mentre per esempi negativi le altre auto che credono non siano auto familiari.
L’apprendimento della classe consiste nel trovare una descrizione che sia condivisa da tutti gli esempi positivi e da nessuno degli esempi negativi.
Così facendo, possiamo fare una previsione: data un’auto che non abbiamo visto prima, verificando con la descrizione appresa, potremo dire se si tratta di un’auto di famiglia oppure no. Oppure possiamo estrarre della conoscenza e l’obiettivo potrebbe essere quello di capire cosa le persone si aspettano da un’auto di famiglia.
Dopo alcune discussioni con esperti del settore, diciamo che si arriva alla conclusione che tra tutte le caratteristiche che può avere un’auto, le caratteristiche che separano un’auto di famiglia dalle altre auto sono il prezzo e la potenza del motore.
Questi due attributi sono gli input per il riconoscitore di classe.
Nota: Stiamo considerando gli altri attributi come irrilevanti.
Sebbene si possa pensare ad altri attributi come il numero di posti a sedere e il colore che potrebbero essere importanti per distinguere tra i tipi di auto, prenderemo in considerazione solo il prezzo e la potenza del motore per mantenere questo esempio semplice.
Ogni punto identificato dalla coppia (prezzo, motore) corrisponde ad un’auto di esempio. Il simbolo “+” denota un esempio positivo della classe mentre con “-” identifichiamo un esempio negativo ovvero un’auto non appartenente alla classe delle auto di famiglia.
Indichiamo il prezzo come primo attributo di input e la potenza del motore come secondo attributo (ad es. volume del motore in centimetri cubi), quindi rappresentiamo ciascuna auto utilizzando due valori numerici.
la sua etichetta ne denota il tipo.
Ogni auto è rappresentata da una tale coppia ordinata (x,r) e il training set contiene N di questi esempi
dove t rappresenta diversi esempi nell’insieme; non rappresenta il tempo o un ordine del genere
I nostri dati di allenamento possono ora essere tracciati nello spazio-bidimensionale :
dove ogni istanza t è un punto dati di coordinate
e il suo tipo, cioè positivo o negativo, è dato da
Dopo ulteriori analisi dei dati, potremmo avere motivo di ritenere che, affinché un’auto sia un’auto di famiglia, il suo prezzo e la potenza del motore dovrebbero rientrare in un determinato intervallo:
L’equazione assume quindi che C sia un rettangolo nello spazio bidimensionale di (Potenza Motore , Prezzo)
Inoltre, l’equazione, fissa l’ipotesi con cui descrivere C, cioè come l’insieme dei rettangoli.
L’ipotesi di classe, quindi, è corretta se per un input x, se e solo se h(x) = 1 per x positivo.
Supponiamo di avere un insieme di dati di addestramento X che è un sottoinsieme di tutti i possibili input, l’errore dell’ipotesi h dato il set di addestramento X è:
L’ ipotesi di classe H è l’insieme dei possibili rettangoli. Ogni quadrupla
definisce un‘ ipotesi H e quello che a noi serve è capire quali sono i valori migliori della quadrupla . In altre parole, dobbiamo trovare i valori di questi 4 parametri partendo dall’insieme di dati di addestramento tale che:
il rettangolo risultante possa includere solo esempi positivi ed escludere quelli negativi.
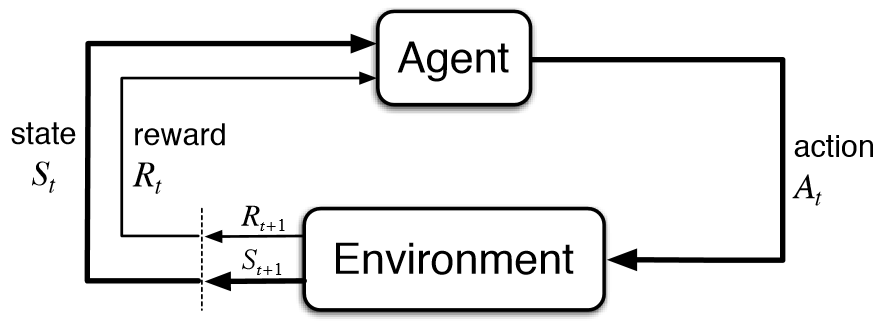
In alcune applicazioni l’output è rappresentato da una sequenza di azioni, in tal caso una singola azione non è importante, ciò che conta è la policy ovvero la sequenza di azioni corrette per raggiungere l’ obiettivo: un’azione è buona se fa parte di una buona politica.
In tal caso, il programma di Machine Learning dovrebbe essere in grado di valutare la bontà delle politiche e imparare dalle buone sequenze di azioni passate per essere in grado di generare una politica efficace.
Tali metodi di rinforzo dell’apprendimento sono chiamati algoritmi di apprendimento per rinforzo.
Un buon esempio è il gioco in cui una singola mossa di per sé non è così importante; è la sequenza di mosse giuste che è buona.
Una mossa è buona se fa parte di una buona politica di gioco.
Il gioco è una ricerca importante sia nell’intelligenza artificiale che nell’apprendimento automatico.
Questo perché i giochi sono facili da descrivere e, allo stesso tempo, sono piuttosto difficili da giocare bene.
Un gioco come gli scacchi ha un numero limitato di regole ma è molto complesso a causa del gran numero di mosse possibili in ogni stato e grande numero di mosse che un gioco contiene.
Una volta che abbiamo buoni algoritmi che possono imparare a giocare bene, possiamo applicarli anche ad applicazioni con utilità economica più evidente.
Un robot che naviga in un ambiente alla ricerca di una posizione obiettivo è un’altra area di applicazione dell’apprendimento per rinforzo.
In qualsiasi momento, il robot può muoversi in una delle numerose direzioni. Dopo una serie di prove, dovrebbe apprendere la corretta sequenza di azioni per raggiungere lo stato finale da uno stato iniziale, facendo questo il più rapidamente possibile e senza colpire nessuno degli ostacoli.
Un fattore che rende più difficile l’apprendimento per rinforzo è quando il sistema ha informazioni sensoriali inaffidabili e parziali. Ad esempio, un robot dotato di videocamera ha informazioni incomplete e quindi in qualsiasi momento si trova in uno stato parzialmente osservabile e dovrebbe decidere tenendo conto di questa incertezza ; ad esempio, potrebbe non conoscere la sua posizione esatta in una stanza, ma solo che c’è un muro alla sua sinistra. Un’attività può anche richiedere un’operazione simultanea di più agenti che dovrebbero interagire e cooperare per raggiungere un obiettivo comune.
Un esempio è una squadra di robot che giocano a calcio.
Nell’apprendimento supervisionato, l’obiettivo è apprendere un collegamento tra input e output grazie ai valori corretti (Training Set o dati di addestramento) forniti da un supervisore.
Nell’apprendimento non supervisionato, non esiste tale supervisore per cui abbiamo solo dati di input e l’obiettivo è quello di trovare una regolarità nell’input.
C’è una struttura nello spazio di input tale che alcuni pattern (o gruppi) si verificano più spesso di altri e vogliamo identificarli al fine di vedere cosa succede generalmente e cosa no in determinate circostanze.
In statistica, questo si chiama stima della densità.
Un metodo per la stima della densità si chiama clustering il cui obiettivo è appunto quello di trovare cluster o raggruppamenti di input.
Vediamo un esempio di applicazione di clustering per l’apprendimento non supervisionato:
Nel caso di un’azienda i dati dei clienti contengono sia le informazioni demografiche che le transazioni, e si potrebbe voler vedere la distribuzione del profilo dei clienti, per identificare il tipo di clienti che è maggiormente presente. In tal caso, un modello di clustering raggruppa clienti simili in base ai loro attributi nello stesso gruppo, fornendo all’azienda raggruppamenti naturali dei suoi clienti, questo è chiamato segmentazione dei clienti. Una volta trovati tali gruppi, l’azienda può decidere strategie, ad esempio, servizi e prodotti, specifici per diversi gruppi, questo è noto come gestione delle relazioni con i clienti. Tale raggruppamento consente anche di identificare quelli che sono “outlier”, cioè quelli che sono diversi dagli altri clienti, il che può implicare una nicchia di mercato che può essere ulteriormente sfruttata dall’azienda.
Nel clustering di documenti, lo scopo è raggruppare documenti simili. Ad esempio, le notizie possono essere suddivise in quelle relative a politica, sport, moda, arte e così via. Comunemente, un documento è rappresentato come un insieme di parole, ovvero, predefiniamo un lessico di N parole e ogni documento è un vettore binario N-dimensionale il cui elemento i è 1 se la parola i appare nel documento parole come “Di”, “e” e così via, che non sono informativi, non vengono utilizzati. I documenti vengono quindi raggruppati in base al numero di parole condivise. Ovviamente qui è fondamentale come viene scelto il lessico.
Supponiamo di voler realizzare un sistema in grado di prevedere il prezzo di un’auto usata con un sistema di apprendimento automatico.
Gli input sono gli attributi dell’auto (marca, anno, cilindrata, chilometraggio e altre informazioni) che riteniamo influenzino il valore di un’auto mentre l’output è il prezzo dell’auto.
Nota:I problemi in cui l’output è un numero sono problemi di regressione.
Siano X gli attributi dell’auto e Y il prezzo dell’auto.
Rilevando le transazioni passate, possiamo raccogliere dati di addestramento e con un programma di Machine Learning e possiamo adattare una funzione a questi dati per apprendere Y in funzione di X.
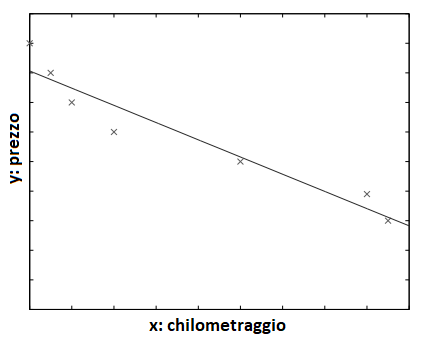
Un esempio è dato nella seguente figura dove la funzione adattata è della forma:
y = wx + w0 per opportuni valori di w e w0.
Modello e training set di previsione del prezzo di auto usate
Nota: L’immagine mostra un set di dati di addestramento delle auto usate. Per semplicità, il chilometraggio viene preso come unico attributo di input e viene utilizzato un modello lineare.
Sia la regressione che la classificazione sono problemi di apprendimento supervisionato in cui c’è un input, X, un output Y.
Il compito è imparare la mappatura dall’input all’output. L’approccio nell’apprendimento automatico consiste nell’ assumere un modello definito e un insieme di parametri:
y = g(x|θ)
dove g(·) è il modello e θ sono i suoi parametri.
Ma tra Classificazione e Regressione vi sono due differenze importanti relative all’output y e al modello g(·):
In un problema di classificazione y è un codice di classe mentre in un problema di regressione è un valore numerico.
In un problema di classificazione g(·) è la funzione discriminante che separa le istanze di classi diverse mentre in un problema di regressione è la funzione di regressione.
Il programma di machine learning ottimizza i parametri, in modo tale che l’errore di approssimazione sia ridotto al minimo, ovvero le nostre stime siano il più vicino possibile ai valori corretti forniti nell’addestramento. Ad esempio, nella figura 1.2, il modello è lineare e w e w0 sono i parametri ottimizzati per il miglior adattamento al training set.
Nei casi in cui il modello lineare è troppo restrittivo, si può usare ad esempio un modello quadratico o un polinomio di ordine superiore, o qualsiasi altra funzione non lineare dell’input, questa volta ottimizzando i suoi parametri per il miglior adattamento.
L’ applicazione più semplice di Pattern Recognition consiste nel riconoscimento ottico dei caratteri partendo dalle loro immagini.
In questo esempio vi sono più classi, e precisamente tanti quanti sono i caratteri che vorremmo riconoscere.
Particolarmente interessante è il caso in cui i caratteri sono scritti a mano, in quanto le persone hanno stili di scrittura diversi: i caratteri possono essere scritti piccoli o grandi, inclinati, con una penna o una matita, e ci sono molte possibili immagini corrispondenti allo stesso carattere.
Sebbene la scrittura sia un’invenzione umana, non disponiamo di alcun sistema affidabile quanto un lettore umano, e non abbiamo una descrizione formale, ad esempio, di “A” che copra tutte le lettere “A” e nessuna delle non “A”.
In questo scenario, prendiamo campioni dagli scrittori (set di addestramento) e impariamo una definizione (regola) di “A” e delle “non A” da questi esempi. Anche se non sappiamo cosa rende un’immagine una “A”, siamo certi che tutte quelle “A” distinte hanno qualcosa in comune, che è ciò che vogliamo estrarre dagli esempi. Sappiamo che l’immagine di un carattere non è solo una raccolta di punti casuali, è una raccolta di tratti con una regolarità che possiamo catturare con un programma di Machine Learning.
Se stiamo leggendo un testo, un fattore di cui possiamo avvalerci è la ridondanza nei linguaggi umani. Una parola è una sequenza di caratteri e i caratteri successivi non sono indipendenti ma sono vincolati dalle parole della lingua. Questo ha il vantaggio che anche se non siamo in grado di riconoscere un carattere, possiamo comunque leggere la parola. Tali dipendenze contestuali possono verificarsi anche a livelli superiori, tra parole e frasi, attraverso la sintassi e la semantica della lingua. Esistono algoritmi di apprendimento automatico per apprendere sequenze e modellare tali dipendenze.
Riconoscimento Facciale
Il riconoscimento facciale è un problema più complesso rispetto al riconoscimento dei caratteri, in questo caso l’input è un’immagine e le classi sono persone da riconoscere, e il programma di apprendimento dovrebbe imparare ad associare le immagini dei volti alle identità.
Ma perché il riconoscimento facciale è più difficile rispetto al riconoscimento dei caratteri?
Nel riconoscimento facciale ci sono più classi, l’immagine in ingresso è più grande e un viso è tridimensionale, le differenze di posa e illuminazione causano cambiamenti significativi nell’immagine. Inoltre, potrebbe anche esserci l’eliminazione o la modifica di alcuni dettagli del volto; ad esempio, gli occhiali possono nascondere gli occhi e le sopracciglia e la barba può nascondere il mento.
Diagnosi Medica
Nella diagnosi medica, gli input sono le informazioni rilevanti che abbiamo sul paziente e le classi sono le malattie. Gli input contengono l’età, il sesso, l’anamnesi del paziente e i sintomi attuali.
Alcuni test potrebbero non essere stati applicati al paziente, e quindi questi input mancherebbero. I test richiedono tempo, possono essere costosi e possono disturbare il paziente; quindi, potrebbero non essere applicati a meno che non forniscano informazioni preziose. Nel caso di una diagnosi medica, un errore di decisione può portare a un trattamento sbagliato o nullo, e in caso di dubbio è preferibile che il classificatore rifiuti e rimandi la decisione a un esperto umano.
Riconoscimento vocale
Nel riconoscimento vocale, l’input è acustico e le classi sono parole che possono essere pronunciate, questa volta l’associazione da apprendere è da un segnale acustico a una parola di una lingua.
Persone diverse, a causa delle differenze di età, sesso o accento, pronunciano la stessa parola in modo diverso, il che rende il riconoscimento vocale piuttosto difficile, e alcune parole sono più lunghe di altre. Le informazioni acustiche aiutano solo fino a un certo punto e, come nel riconoscimento ottico dei caratteri, l’integrazione di un “modello linguistico” è fondamentale nel riconoscimento vocale e il modo migliore per elaborare un modello linguistico è di nuovo imparandolo da un ampio set di dati di esempio.
Traduzione
Dopo decenni di ricerca sulle regole di traduzione codificate a mano, è diventato evidente di recente che la tecnica più promettente consiste nel fornire un numero molto elevato di coppie di esempio di testi tradotti e fare in modo che un programma individui automaticamente le regole per mappare una stringa di caratteri su un’altra.
Biometria
La biometria è il riconoscimento o l’autenticazione di persone utilizzando le loro caratteristiche fisiologiche e/o comportamentali che richiede un’integrazione di input provenienti da diverse modalità. Esempi di caratteristiche fisiologiche sono le immagini del viso, delle impronte digitali, dell’iride e del palmo; esempi di caratteristiche comportamentali sono le dinamiche di firma, voce, andatura e colpo di chiave.
A differenza delle consuete procedure di identificazione – foto, firma stampata o password – quando ci sono molti input diversi (non correlati), le falsificazioni (spoofing) sarebbero più difficili e il sistema sarebbe più accurato, si spera senza troppi inconvenienti per gli utenti.
Il Machine Learning viene utilizzato sia nei riconoscitori separati per queste diverse modalità sia nella combinazione delle loro decisioni per ottenere una decisione generale di accettazione/rifiuto, tenendo conto dell’affidabilità di queste diverse fonti. L’apprendimento di una regola dai dati consente anche l’estrazione della conoscenza.
Conclusioni
La regola è un semplice modello che spiega i dati e una volta appreso il discriminante che identifica una specifica classe, abbiamo la conoscenza delle proprietà di quella specifica classe che ci permette di distinguerla dalle altre.
L’apprendimento della regola consente anche la compressione in quanto adattando una regola ai dati, otteniamo una spiegazione più semplice dei dati, che richiede meno memoria e meno calcoli. Una volta che hai le regole di addizione, non è necessario ricordare la somma di ogni possibile coppia di numeri.
Per Classificazione si intende un’attività che richiede l’uso di algoritmi di Machine Learning che apprendono come assegnare un’etichetta di classe agli esempi dal dominio del problema.
Facciamo un esempio pratico.
Un credito è una somma di denaro prestata da un istituto finanziario, ad esempio una banca, da restituire con gli interessi, generalmente a rate.
È importante che la banca sia in grado di prevedere in anticipo il rischio connesso ad un prestito, che è la probabilità che il cliente vada in default e non restituisca l’intero importo, sia per assicurarsi che la banca realizzi un profitto e anche per non infastidire un cliente con un prestito oltre la sua capacità finanziaria.
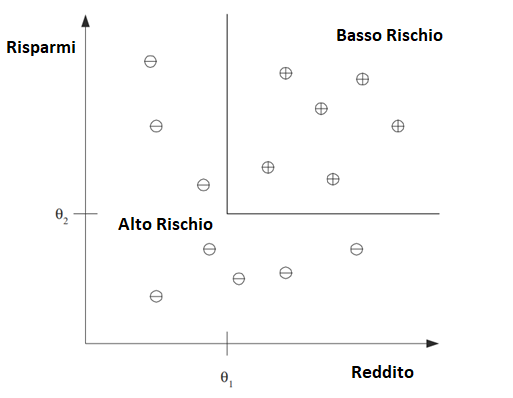
Nel credit scoring, la banca calcola il rischio dato l’importo del credito e le informazioni sul cliente. Le informazioni sul cliente includono dati a cui abbiamo accesso e sono rilevanti per il calcolo della sua capacità finanziaria, vale a dire, reddito, risparmi, garanzie reali, professione, età, storia finanziaria passata, ecc. La banca ha un registro dei prestiti passati contenente tali dati del cliente e se il prestito è stato rimborsato o meno. Da questi dati, lo scopo è quello di inferire una regola generale che codifica l’associazione tra gli attributi di un cliente e il suo rischio, ovvero il sistema di Machine Learning adatta un modello ai dati passati per poter calcolare il rischio per una nuova applicazione e quindi decide di accettare o rifiutarlo di conseguenza.
Questo è un esempio di problema di classificazione in cui sono presenti due classi:
clienti a basso rischio
clienti ad alto rischio.
Le informazioni su un cliente costituiscono l’input per il classificatore il cui compito è assegnare l’input a una delle due classi.
Dopo l’addestramento con i dati passati (training set), una regola di classificazione appresa può essere della forma:
IF (reddito > θ1 AND risparmi > θ2)
THEN
basso rischio
ELSE
alto rischio
per opportuni valori di θ1 e θ2 .
Questo è un esempio di discriminante; è una funzione che separa gli esempi di diverse previsioni. Avendo una regola come questa, l’applicazione principale è la previsione: una volta che abbiamo una regola che si adatta ai dati passati, se il futuro è simile al passato, allora possiamo fare previsioni corrette per nuove istanze.
Data una nuova applicazione con un certo reddito e risparmio, possiamo facilmente decidere se è a basso rischio o ad alto rischio. In alcuni casi, invece di fare un 0/1 (basso rischio/alto rischio), potremmo voler calcolare una probabilità, ovvero P(Y|X), dove X sono gli attributi del cliente e Y è rispettivamente 0 o 1 per il rischio basso o rischio alto.
P(Y=0/X=x) è la probabilità che il cliente X riesca a pagare
P(Y=1/X=x) è la probabilità che il cliente X NON riesca a pagare
Da questo punto di vista, possiamo vedere la classificazione come l’Apprendimento di un’Associazione da X a Y. Allora per un dato X = x, se abbiamo P(Y = 1|X = x) = 0.8, diciamo che il cliente ha un 80 percentuale di probabilità di essere ad alto rischio, o equivalentemente una probabilità del 20% di essere a basso rischio. Decidiamo quindi se accettare o rifiutare il prestito a seconda di t lui possibile guadagno e perdita.
Questo è un esempio di discriminante, è una funzione che separa gli esempi di diverse previsioni. Per una regola come questa, l’applicazione principale è la previsione: una volta che abbiamo una regola che si adatta ai dati passati, se il futuro è simile al passato, allora possiamo fare previsioni corrette per nuove istanze.
Segue una figura che mostra l’output di questa classificazione
L’Association Learning è una tecnica di Machine Learning e Data Mining basata su regole che trova importanti relazioni tra variabili o funzionalità in un set di dati.
Facciamo un esempio pratico.
Nel caso della vendita al dettaglio di una catena di supermercati, un’applicazione di Association Learning è l’analisi del paniere che consiste nel trovare associazioni tra i prodotti acquistati dai clienti: se le persone che acquistano X in genere acquistano anche Y e se c’è un cliente che acquista X e non compra Y, è un potenziale cliente Y.
Una volta trovati tali clienti, possiamo indirizzarli grazie al cross-selling all’acquisto di prodotti o servizi aggiuntivi correlati al prodotto precedentemente acquistato.
Nel trovare una regola di associazione, siamo interessati ad apprendere una probabilità condizionata della forma P(Y|X) dove Y è il prodotto su cui vorremmo condizionare X, che è il prodotto o l’insieme di prodotti che sappiamo che il cliente ha già acquistato.
Diciamo che, ripassando i nostri dati, calcoliamo che P(chips|birra) = 0,7, quindi possiamo definire la regola:
Il 70% dei clienti che acquistano birra acquista anche patatine.
Potremmo voler fare una distinzione tra i clienti e, a tal fine, stimare P(Y|X,D) dove D è l’insieme degli attributi del cliente, ad esempio sesso, età, stato civile e così via, supponendo di avere accesso a queste informazioni. Se si tratta di una libreria anziché di un supermercato, i prodotti possono essere libri o autori. Nel caso di un portale Web, gli articoli corrispondono a collegamenti a pagine Web e possiamo stimare i collegamenti che un utente potrebbe fare clic e utilizzare queste informazioni per scaricare tali pagine in anticipo per un accesso più rapido.
L’applicazione di strategie di Machine Learning su database di grandi dimensioni si chiama Data Mining.
L’analogia è che da una miniera (database di grande dimensione) venga estratta una grande quantità di terra che porta con sé una piccola quantità di materiale molto prezioso; allo stesso modo, nel data mining, un grande volume di dati viene elaborato per costruire un modello semplice con un uso prezioso, ad esempio, con un’elevata precisione predittiva.
Il data mining (letteralmente dall’inglese estrazione di dati) è l’insieme di tecniche e metodologie che hanno per oggetto l’estrazione di informazioni utili da grandi quantità di dati (es. banche dati, datawarehouse, ecc.), attraverso metodi automatici o semi-automatici (es. apprendimento automatico) e l’utilizzo scientifico, aziendale, industriale o operativo delle stesse.
Gli scenari in cui le tecniche di Data Mining vengono utilizzate per adottare strategie basate sul Machine Learning sono abbondanti e possono riguardare:
Le banche finanziarie analizzano i loro dati passati per costruire modelli da utilizzare nelle richieste di credito, rilevamento delle frodi e mercato azionario.
Nella produzione, i modelli di apprendimento vengono utilizzati per l’ottimizzazione, il controllo e la risoluzione dei problemi.
In medicina, i programmi di apprendimento vengono utilizzati per la diagnosi medica.
Nelle telecomunicazioni, i modelli vengono analizzati per l’ottimizzazione della rete e per massimizzare la qualità del servizio.
Nella scienza, grandi quantità di dati in fisica, astronomia e biologia possono essere analizzati abbastanza velocemente dai computer.
Il World Wide Web è enorme, è in costante crescita e la ricerca di informazioni rilevanti non può essere eseguita manualmente.
L’apprendimento automatico ci aiuta anche a trovare soluzioni a molti problemi di visione, riconoscimento vocale e robotica. Prendiamo l’esempio del riconoscimento dei volti: questo è un compito che svolgiamo senza sforzo; ogni giorno riconosciamo familiari e amici guardando i loro volti o dalle loro fotografie, nonostante le differenze di posa, illuminazione, acconciatura e così via.
Ma lo facciamo inconsciamente e non siamo in grado di spiegare come lo facciamo. Poiché non siamo in grado di spiegare la nostra esperienza, non possiamo scrivere il programma per computer. Allo stesso tempo, sappiamo che un’immagine del viso non è solo un casuale raccolta di pixel; un viso ha una struttura. È simmetrico. Ci sono gli occhi, il naso, la bocca, situati in determinati punti del viso. Il viso di ogni persona è un modello composto da una particolare combinazione di questi.
Estraendo informazioni da un database di grandi dimensioni (data mining) che include immagini del viso di una specifica persona, potremmo utilizzare un programma di Machine Learning che cattura il modello specifico di quella persona e quindi riconosce controllando questo modello in una data immagine.
Questo è un esempio di riconoscimento del modello.
Come abbiamo appena visto, il Machine Learning oltre al Data Mining include anche metodologie e tecniche di intelligenza artificiale.
Infatti, per essere intelligente, un sistema che si trova in un ambiente in evoluzione dovrebbe avere la capacità di apprendere. Se il sistema può apprendere e adattarsi a tali cambiamenti, il progettista di sistema non deve prevedere e fornire soluzioni per tutte le possibili situazioni.
Il Machine Learning consiste nella programmazione di computer per ottimizzare un criterio di prestazione utilizzando dati di esempio o esperienze passate.
Abbiamo un modello definito mediante alcuni parametri e l’apprendimento è l’esecuzione di un programma per computer per ottimizzare i parametri del modello utilizzando i dati di addestramento o il passato esperienza.
Il modello può essere predittivo per fare previsioni in futuro, o descrittivo per acquisire conoscenze dai dati, o entrambi. Più nello specifico, Il Machine Learning utilizza la teoria della statistica nella costruzione di modelli matematici, perché il compito principale è fare inferenze da un campione.
Il ruolo dell’informatica, quindi, è duplice: in primo luogo, nella fase di training, abbiamo bisogno di algoritmi efficienti per archiviare ed elaborare l’enorme quantità di dati che generalmente abbiamo. In secondo luogo, una volta appreso un modello, anche la soluzione algoritmica per l’inferenza deve essere efficiente.
Utilizziamo i cookie sul nostro sito Web per offrirti l'esperienza più pertinente ricordando le tue preferenze e le visite ripetute. Cliccando su “Accetta tutto” acconsenti all'uso di TUTTI i cookie. Tuttavia, puoi visitare "Cookie Setting" per fornire un consenso controllato.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Durata
Descrizione
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.