Solitamente quando ci troviamo davanti ad un problema che vogliamo risolvere mediante l’utilizzo di un computer ci serve un algoritmo. Un algoritmo è una sequenza di istruzioni necessaria a trasformare l’input in output.
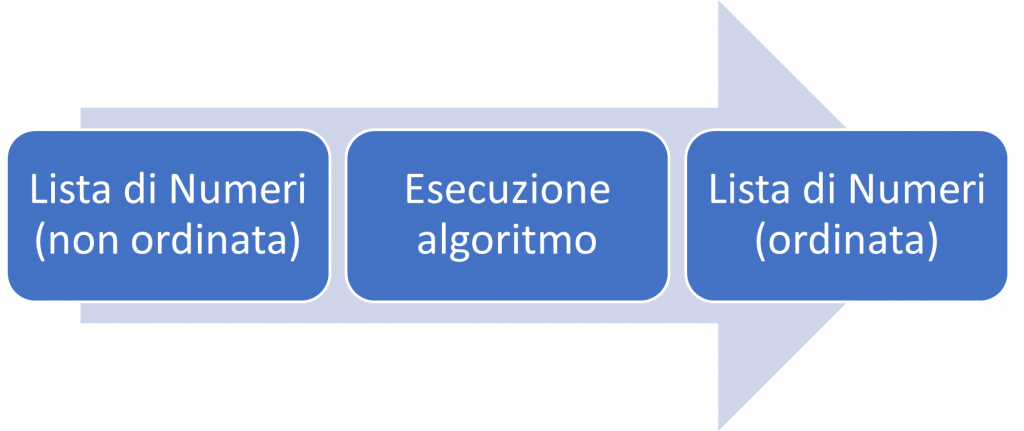
Ad esempio, se volessimo ordinare un insieme di numeri abbiamo bisogno di un algoritmo di ordinamento il cui input è la lista di numeri che si vuole ordinare e l’output consiste nella corrispondente lista ordinata. Per questo compito, possono esserci vari algoritmi (ad esempio Merge Sort, Bubble Sort, Insertion Sort etc.) e potremmo essere interessati a trovare quello più efficiente, che richiede il numero minimo di istruzioni o memoria o entrambi.
Segue una figura dell’approccio classico alla risoluzione di un problema noto:
Purtroppo, per alcune attività non disponiamo di un algoritmo come, ad esempio, per l’identificazione delle mail di spam. Sappiamo qual è l’input: un documento di posta elettronica che nel caso più semplice è un file di caratteri. Sappiamo quale sia l’output dovrebbe essere: un output si/no che indica se il messaggio è spam o no. Non sappiamo come trasformare l’input in output. A rendere più ardua l’attività di identificazione delle mail di spam vi è la possibilità che tutto quello che può essere considerato spam cambia nel tempo e da individuo a individuo.
Come possiamo compensare questa mancanza di conoscenza?
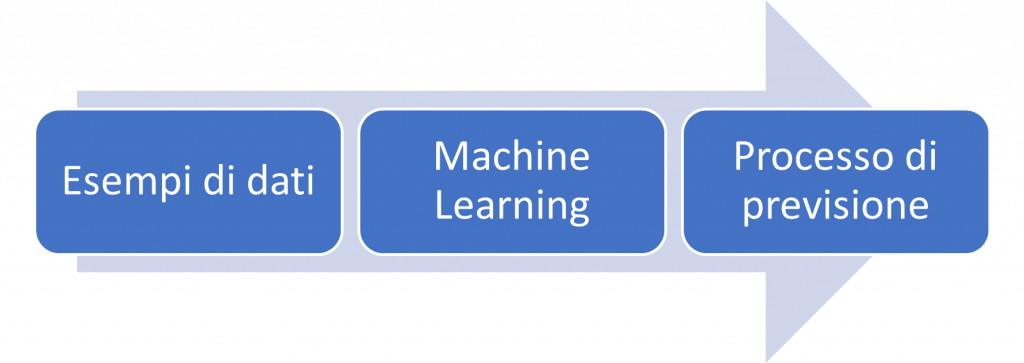
La risposta è nei dati.
Possiamo facilmente compilare migliaia di messaggi di esempio, alcuni dei quali sappiamo essere spam per “imparare” cosa costituisce spam da loro. In altre parole, vorremmo che la macchina estraesse automaticamente l’algoritmo per questo compito.
Ma possiamo utilizzare un approccio simile anche per l’ordinamento dei numeri?
Chiaramente non serve utilizzare un approccio basato sul Machine Learning per l’ordinamento dei numeri perché non c’è bisogno di imparare a ordinare i numeri.
Ci sono molte applicazioni per le quali non abbiamo un algoritmo ma dati di esempio.
Con i progressi della tecnologia informatica, attualmente abbiamo la capacità di archiviare ed elaborare grandi quantità di dati, nonché di accedervi da luoghi fisicamente distanti su una rete di computer.
La maggior parte dei dispositivi di acquisizione dati ora sono digitali e registrano dati in maniera affidabile.
Si pensi, ad esempio, a una catena di supermercati che ha centinaia di negozi in tutto un paese che vendono migliaia di merci a milioni di clienti. I terminali del punto vendita registrano i dettagli di ogni transazione: data, codice identificativo del cliente, merce acquistata e relativo importo, totale spesa e così via. In genere si tratta di gigabyte di dati ogni giorno. Quello che la catena di supermercati vuole è poter prevedere chi sono i probabili clienti di un prodotto Anche in questo caso, l’algoritmo per questo non è evidente, cambia nel tempo e per posizione geografica, i dati memorizzati diventano utili solo quando vengono analizzati e trasformati in informazioni di cui possiamo avvalerci, ad esempio, per fare previsioni.
Sappiamo che esiste un processo che spiega i dati che osserviamo, anche se non conosciamo i dettagli del processo alla base della generazione dei dati. Ad esempio, per il comportamento dei consumatori, sappiamo che non è completamente casuale. Quando comprano birra, comprano patatine, d’estate comprano il gelato.
Quello che possiamo affermare è che nei dati ci sono modelli.
Potremmo non essere in grado di identificare completamente il processo di previsione, ma è possibile costruire una buona e utile approssimazione. Tale approssimazione potrebbe non spiegare tutto, ma potrebbe comunque essere in grado di rendere conto di una parte dei dati.
Anche se l’identificazione del processo completo non dovesse essere possibile potremmo ancora rilevare determinati modelli o regolarità.
Tali modelli possono aiutarci a capire il processo, oppure possiamo usare quei modelli per fare previsioni: supponendo che il futuro, almeno il prossimo futuro, non sarà molto diverso dal passato in cui sono stati raccolti i dati di esempio, anche le previsioni future possono essere corrette.
Questo è l’obiettivo del Machine Learning.
Segue una figura dell’approccio basato sul Machine Learning: